
Oric Lawson
Vendredi après-midi, le projet OpenZFS coffre Version 2.1.0 de notre éternel système de fichiers favori « C’est compliqué mais ça vaut le coup ». La nouvelle version est compatible avec FreeBSD 12.2-RELEASE et versions ultérieures, et les noyaux Linux 3.10-5.13. Cette version introduit plusieurs améliorations de performances générales, ainsi que des fonctionnalités entièrement nouvelles – principalement destinées aux organisations et à d’autres cas d’utilisation très avancés.
Aujourd’hui, nous allons nous concentrer sur la plus grande fonctionnalité ajoutée par OpenZFS 2.1.0 – la topologie dRAID vdev. dRAID est en développement actif depuis au moins 2015 et a atteint le statut bêta lorsque intégré Dans OpenZFS master en novembre 2020. Depuis lors, il a été fortement testé dans plusieurs grands magasins de développement OpenZFS – ce qui signifie que la version d’aujourd’hui est « fraîche » en état de production, et non « nouvelle » comme non testée.
Présentation du RAID distribué (dRAID)
Si vous pensiez déjà que la topologie ZFS était un fichier bateau Sujet, préparez-vous à vous épater. Le RAID distribué (dRAID) est une toute nouvelle topologie vdev que nous avons rencontrée pour la première fois lors d’une présentation au OpenZFS Dev Summit 2016.
Lors de la création d’un vdev dRAID, l’administrateur spécifie le nombre de secteurs de données, de parité et de secours pour chaque bande. Ces nombres sont indépendants du nombre de disques physiques dans vdev. Nous pouvons le voir en pratique dans l’exemple suivant, qui est tiré des concepts de base dRAID Documentation:
root@box:~# zpool create mypool draid2:4d:1s:11c wwn-0 wwn-1 wwn-2 ... wwn-A
root@box:~# zpool status mypool
pool: mypool
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
draid2:4d:11c:1s-0 ONLINE 0 0 0
wwn-0 ONLINE 0 0 0
wwn-1 ONLINE 0 0 0
wwn-2 ONLINE 0 0 0
wwn-3 ONLINE 0 0 0
wwn-4 ONLINE 0 0 0
wwn-5 ONLINE 0 0 0
wwn-6 ONLINE 0 0 0
wwn-7 ONLINE 0 0 0
wwn-8 ONLINE 0 0 0
wwn-9 ONLINE 0 0 0
wwn-A ONLINE 0 0 0
spares
draid2-0-0 AVAILTopologie Dredd
Dans l’exemple ci-dessus, nous avons onze disques : wwn-0 De l’autre côté wwn-A. Nous avons créé un draID vdev avec 2 périphériques de parité, 4 périphériques de données et 1 périphérique de sauvegarde par bande – en langage condensé, draid2:4:1.
Bien que nous ayons onze disques au total dans un fichier draid2:4:1, seuls six sont utilisés dans chaque barre de données — et un dans chaque barre physique – physique – ruban. Dans un monde d’aspirateurs parfaits, de surfaces sans friction et de poules à balles, la disposition sur le disque draid2:4:1 Il ressemblera à ceci:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | une |
| s | s | s | Dr | Dr | Dr | Dr | s | s | Dr | Dr |
| Dr | s | Dr | s | s | Dr | Dr | Dr | Dr | s | s |
| Dr | Dr | s | Dr | Dr | s | s | Dr | Dr | Dr | Dr |
| s | s | Dr | s | Dr | Dr | Dr | s | s | Dr | Dr |
| Dr | Dr | . | . | s | . | . | . | . | . | . |
| . | . | . | . | . | s | . | . | . | . | . |
| . | . | . | . | . | . | s | . | . | . | . |
| . | . | . | . | . | . | . | s | . | . | . |
| . | . | . | . | . | . | . | . | s | . | . |
| . | . | . | . | . | . | . | . | . | s | . |
| . | . | . | . | . | . | . | . | . | . | s |
En effet, Dredd pousse le concept de RAID à « parité diagonale » un peu plus loin. RAID5 n’était pas la première topologie de parité RAID – c’était RAID3, dans lequel la parité était située sur un disque dur, plutôt que répartie sur l’ensemble de la matrice.
RAID5 a éliminé le disque dur de parité et, à la place, a distribué la parité sur tous les disques de matrice, fournissant des écritures aléatoires beaucoup plus rapides que le RAID3 conceptuellement plus simple, car il n’empêchait pas chaque écriture sur un disque de parité dur.
dRAID reprend ce concept – répartir la parité sur tous les disques, plutôt que de tout agréger sur un ou deux disques durs – et l’étend à spares. Si le disque échoue dans dRAID vdev, les secteurs de parité et les données qui résident sur le disque mort sont copiés dans un ou plusieurs secteurs de réserve réservés pour chaque bande affectée.
Prenons le graphique simplifié ci-dessus et voyons ce qui se passe si nous retirons un disque de la matrice. L’échec initial laisse des lacunes dans la plupart des ensembles de données (dans ce schéma simplifié, des lignes) :
| 0 | 1 | 2 | 4 | 5 | 6 | 7 | 8 | 9 | une | |
| s | s | s | Dr | Dr | Dr | s | s | Dr | Dr | |
| Dr | s | Dr | s | Dr | Dr | Dr | Dr | s | s | |
| Dr | Dr | s | Dr | s | s | Dr | Dr | Dr | Dr | |
| s | s | Dr | Dr | Dr | Dr | s | s | Dr | Dr | |
| Dr | Dr | . | s | . | . | . | . | . | . |
Mais lorsque nous utilisons resilver, nous le faisons sur la capacité de réserve précédemment réservée :
| 0 | 1 | 2 | 4 | 5 | 6 | 7 | 8 | 9 | une | |
| Dr | s | s | Dr | Dr | Dr | s | s | Dr | Dr | |
| Dr | s | Dr | s | Dr | Dr | Dr | Dr | s | s | |
| Dr | Dr | Dr | Dr | s | s | Dr | Dr | Dr | Dr | |
| s | s | Dr | Dr | Dr | Dr | s | s | Dr | Dr | |
| Dr | Dr | . | s | . | . | . | . | . | . |
Veuillez noter que ces graphiques sont simplifié. L’image complète comprend des groupes, des segments et des lignes dans lesquels nous n’essaierons pas d’entrer ici. La disposition logique est également mélangée de manière aléatoire pour répartir les éléments uniformément sur les lecteurs en fonction du décalage. Ceux qui s’intéressent aux moindres détails sont encouragés à jeter un œil à ces détails Suspension Dans le code d’origine, commit.
Il convient également de noter que dRAID nécessite des largeurs de bande statiques – pas les largeurs dynamiques prises en charge par les vdevs RAIDz1 et RAIDz2 traditionnels. Si nous utilisons des disques 4kn, le fichier . draid2:4:1 Un vdev comme celui illustré ci-dessus nécessiterait 24 Ko sur disque par bloc de métadonnées, alors qu’un vdev RAIDz2 conventionnel à six largeurs n’a besoin que de 12 Ko. Cet écart s’aggrave au fur et à mesure que les valeurs sont élevées d+p Obtenir draid2:8:1 Il faudrait 40 Ko pour le même bloc de métadonnées !
Pour cette raison, le special L’allocateur vdev est très utile dans les pools avec dRAID vdevs – lorsqu’il y a un pool avec lui draid2:8:1 et trois larges special Il a besoin de stocker un bloc de métadonnées de 4KiB, il le fait en seulement 12Ko sur un fichier special, au lieu de 40 Ko dans un fichier draid2:8:1.
DREAD Performance, tolérance aux pannes et retour sur investissement
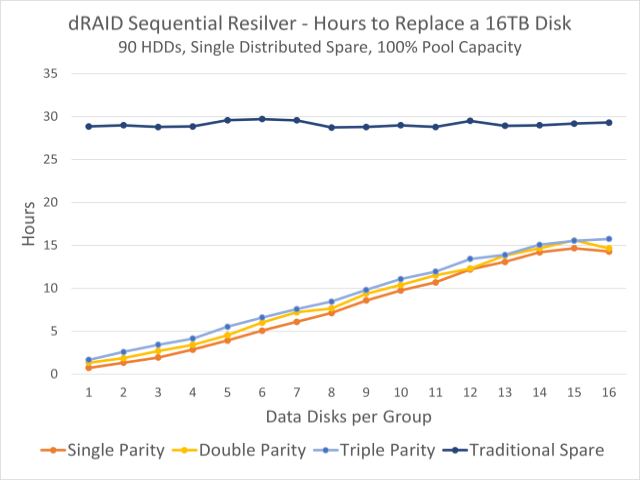
Ce graphique montre les temps de réémergence observés pour un pool de 90 disques. La ligne bleu foncé en haut est le temps de re-filtre sur un disque dur fixe ; Les lignes colorées ci-dessous indiquent les délais de re-liquidation sur la capacité de réserve distribuée.
Pour la plupart, dRAID vdev fonctionnera de la même manière qu’un ensemble équivalent de vdev traditionnels – par exemple, draid1:2:0 Sur neuf disques, cela fonctionnera presque de manière équivalente à un ensemble de trois vdev RAIDz1 de largeur 3. La tolérance aux pannes est également similaire – vous êtes assuré de survivre à une seule panne avec p=1, tout comme vous l’êtes avec les vdevs RAIDz1.
Notez que nous avons dit que la tolérance aux pannes est similaire, n’étaient pas identiques. Un ensemble traditionnel de trois vdev RAIDz1 de largeur 3 ne garantit qu’une seule panne de disque, mais survivra probablement à une seule panne de disque – tant que le deuxième disque défaillant ne fait pas partie du même vdev que le premier, tout est bien.
en neuf disques draid1:2, une deuxième panne de disque tuerait presque certainement vdev (et le bundle qui l’accompagne), si Cet échec se produit avant que vous ne surviviez. Puisqu’il n’y a pas d’ensembles fixes de polices individuelles, il est très probable qu’une deuxième panne de disque désactivera des secteurs supplémentaires dans des polices déjà dégradées, indépendamment de Lequel Le deuxième disque a échoué.
Ce manque de tolérance aux pannes est quelque peu compensé par des temps de réargenture exponentiellement plus rapides. Dans le graphique en haut de cette section, nous pouvons voir que dans un lot de quatre-vingt-dix disques de 16 To, vous faites basculer une machine stationnaire conventionnelle. spare Cela prend environ trente heures quelle que soit la façon dont nous configurons dRAID vdev – mais réapparaître sur la redondance distribuée peut prendre moins d’une heure.
Cela est largement dû au reformatage sur une partition distribuée qui divise la charge d’écriture entre tous les disques restants. Lorsque vous le portez dans un style traditionnel spare, le disque de sauvegarde lui-même est un goulot d’étranglement – les lectures proviennent de tous les disques de vdev, mais toutes les écritures doivent être effectuées avec la sauvegarde. Mais lorsque la capacité redondante distribuée est repensée, les deux sont lus Et le Les charges de travail d’écriture sont réparties entre tous les disques restants.
Un resilver distribué peut également être un resilver série, plutôt qu’un processeur de resilver – ce qui signifie que ZFS peut simplement copier tous les secteurs affectés, sans se soucier de ce que blocks Ces secteurs appartiennent à. En revanche, les réargenteurs de réparation doivent analyser l’intégralité de l’arborescence des blocs, ce qui entraîne une charge de travail de lecture aléatoire plutôt qu’une charge de travail de lecture séquentielle.
Lorsque le remplacement physique du disque défaillant est ajouté à l’assemblage, cette revente volonté C’est scalaire, pas séquentiel – et cela étouffera les performances d’écriture d’un disque de rechange individuel, plutôt que celles de l’ensemble du vdev. Mais le temps pour terminer ce processus est beaucoup moins important, car vdev n’est même pas dans un état de dégradation.
Conclusion
Les versions distribuées RAID vdevs sont souvent destinées aux gros serveurs de stockage – OpenZFS draid La conception et les tests ont largement tourné autour des systèmes à 90 disques. À plus petite échelle, les fichiers vdevs traditionnels et spares Il reste aussi utile qu’avant.
Nous avertissons particulièrement les débutants en stockage d’être prudents avec eux draid— C’est une disposition beaucoup plus complexe que la mise en commun avec des vdev traditionnels. La flexibilité rapide est excellente – mais draid Il réussit à la fois dans les niveaux de stress et dans certains scénarios de performance en raison de ses lignes de longueur nécessairement fixes.
Alors que les disques traditionnels continuent d’augmenter en taille sans augmenter significativement les performances, draid Sa reconfiguration rapide peut devenir souhaitable même sur des systèmes plus petits – mais il faudra un certain temps pour déterminer exactement où commence le point idéal. En attendant, n’oubliez pas que RAID n’est pas une sauvegarde – cela inclut draid!

« Music lover. Gamer. Alcoholist. Professional reader. Web specialist. »